再用pd.read_csv读取大文件时,如果文件太大,会出现memoryerror的问题。
解决办法一:pd.read_csv的参数中有一个chunksize参数,为其赋值后,返回一个可迭代对象TextFileReader,对其遍历即可
reader = pd.read_csv(file_path, chunksize=20) # 每次读取20条数据
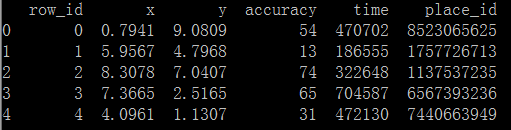
1 import pandas as pd 2 3 def knn(): 4 # 读取数据 5 file_path = './facebook/train.csv' 6 7 reader = pd.read_csv(file_path, chunksize=20) # 每块为20条数据(index) 8 9 for chunk in reader:10 print(chunk)11 break12 13 if __name__ == '__main__':14 knn()
代码执行结果如下:
解决办法二:pd.read_csv的参数中有一个iterator参数,默认为False,将其改为True,返回一个可迭代对象TextFileReader,使用它的get_chunk(num)方法可获得前num行的数据
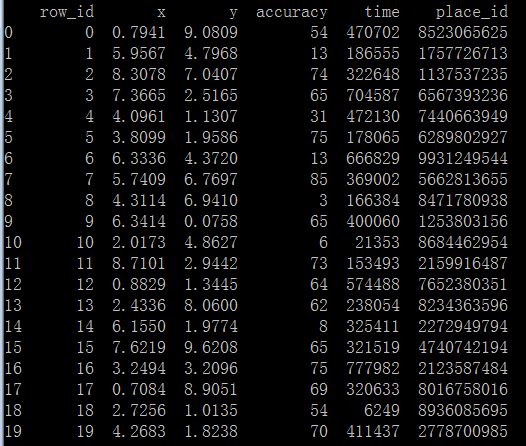
import pandas as pd def knn(): '''完成k近邻算法''' # 读取数据 file_path = './facebook/train.csv' reader = pd.read_csv(file_path, iterator=True) chunk = reader.get_chunk(5) # 获取前5行数据 print(chunk)if __name__ == '__main__': knn()
代码执行结果如下: